Retrieving historical financial data from MorningStar Using PythonMorning star website contains all the historical financial data such as Net income, EPS (earning per share) per year over 10 years for each stocks. It also provides the historical valuation data such as historical P/E and P/B which are quite difficult to source for. The purpose of the following script is to retrieve the historical data of all desired stocks in a format that is easily represented in Tableau for interactive representation. Below stock information are only catered for Singapore stocks but can be easily changed to other regions as will be shown below.
The first part is to retrieve the company historical financial stats. MorningStar website provides an option to download the data in excel or CSV format. Retrieving in csv format allows easy cleaning and subsequent formatting of the data. To obtain the url for the excel downloading, use any browser and open the developer tab. The network tab will display the url for the excel after pressing on the excel/csv download button. The url will be as below format. Note the region (in blue) can be changed for stocks in another region.
http://financials.morningstar.com/ajax/exportKR2CSV.html?&callback=?&t=XSES:STOCKSYMBOL®ion=sgp&culture=en-US&cur=&order=asc
To download and process the information, two major modules are required: python pattern and Python Pandas. Python pattern to handle most of the HTML calls and requests while Pandas to handle the data cleaning and formatting.
For the first part of data extraction, the downloading will be in csv format and using pandas to read the csv. A couple of things to take notes for pulling the data for the first set.
- Due to the different line formats, some of the lines are skipped when using pandas to read from csv.
- Revenue, income and dividend may be in native currencies for different stocks hence giving rise to different column names (Column names will have the currency displayed). For each of the different currencies, remove the currencies label and consolidate all under same column and extra column for the currency values.
- The excel default to two decimal places. Extra calculation are needed to get the actual values without rounding off.
For the second part of retrieving the historical valuation, the method of getting the table will be different as there is no default csv file to be download. In this case, will have to make use of the pandas io html table read function. This pandas method will convert any table like object (html tag td, tr) in website to DataFrame. Some processing is required when pulling this table as it is not a conventional table format. It requires ignoring some lines, renaming the columns and transposing the table.
pandas.io.html.read_html(url_html, tupleize_cols = True,header=0 )
The process is looped over the various stocks hence the full range of stocks can be retrieved. In addition, the information can be combined with the SG company stock information such as industries etc. Information on how to retrieve the SG company stock information such as current price, current valuation etc are available in the following post “Retrieving stock news and Ex-date from SGX using python”.
The full data can be displayed in Tableau as shown bleow. You can also view the interactive mode (WordPress does not allow interactive mode) in my other blog. The script are available in GitHub.
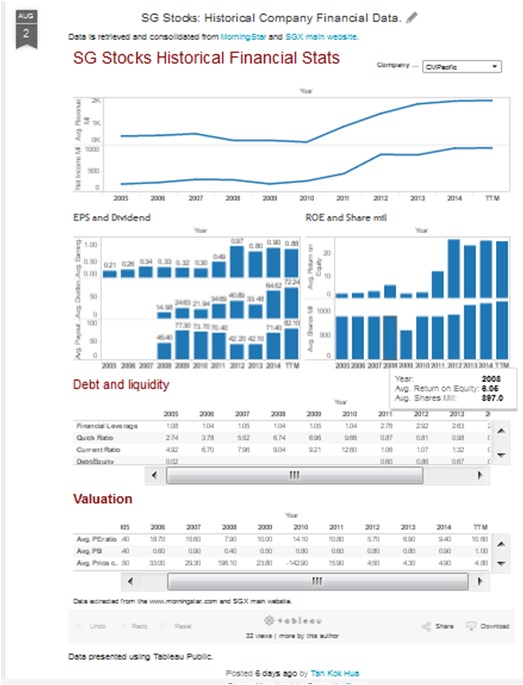

More SG stocks information with tableau display are found in http://sgstocksdata.blogspot.sg
I used to use google sheet’s extracthtml formula to take the table from gurufocus. but it seems morningstar doesn’t identify the data as “table”. is there any other way to extract the data from morningstar without going through the python script?
I not really sure how the extracthtml works. Perhaps you can provide the function parameters to me and I will help take a look?
Hi , the below link does work for me. indeed when i run the code it says ‘problem downloading the file’. any help? maybe updated address?
http://financials.morningstar.com/ajax/exportKR2CSV.html?&callback=?&t=XSES:aapl®ion=usa&culture=en-US&cur=&order=asc
Hi mbpro, thanks for pointing it out. The address is changed to below:
http://financials.morningstar.com/finan/ajax/exportKR2CSV.html?&callback=?&t=XSES:N4E®ion=sgp&culture=en-US&cur=&order=asc
Hi , the below link does work for me. indeed when i run the code it says ‘problem downloading the file’. any help? maybe updated address?
http://financials.morningstar.com/finan/ajax/exportKR2CSV.html?&callback=?&t=XSES:N4E®ion=sgp&culture=en-US&cur=&order=asc
Hi Jian He, seems like morningstar no longer offers the option to download data as CSV in their website. I can’t seem to find the download link. If this is disable, then the link will not work.
Do you have work around solution for that?
Hi, the other way is to scrape the pages using requests and BeautifulSoup. I have not got around to explore the feasibility of scraping it but it worth a try. Hope that helps.