Google sheets simplify the process of web scraping especially for table and list elements. For below project, the purpose is to obtain common/essential words and their corresponding definitions for GMAT/GRE preparations.
Below are examples of each.
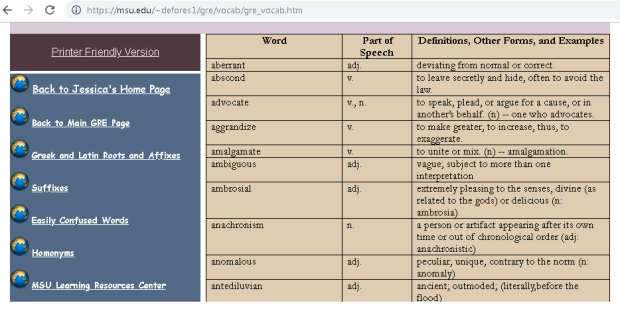
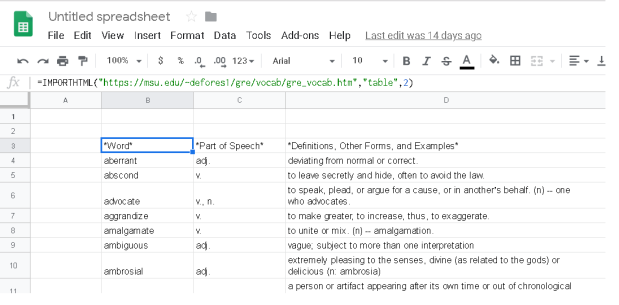
Table type extraction (source)
In one of the cells, type in =IMPORTHTML(“url-site“,“table”,<table_id>) where <table_id> is the table position in the url (either guess or iterate from 1 to XXX etc or use chrome developer tools to count the table num)
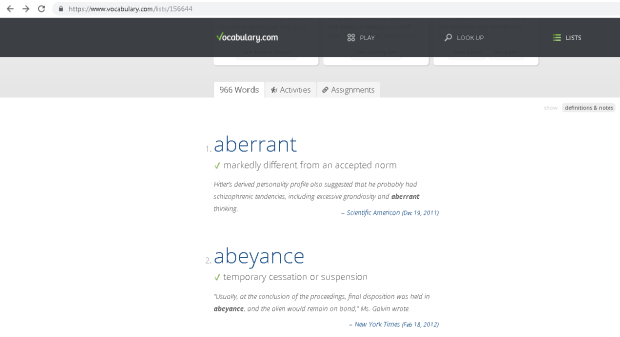
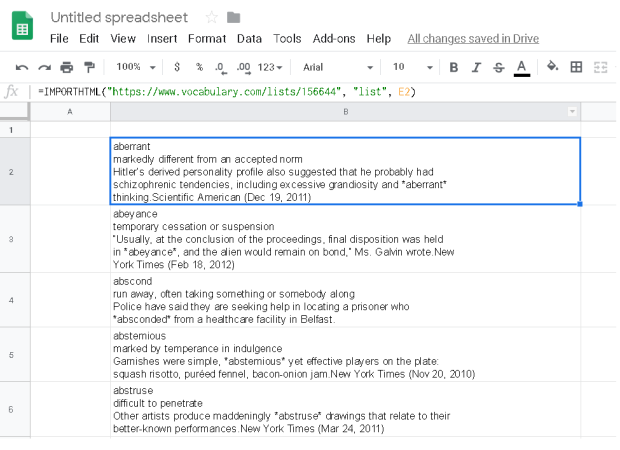
List Type Extraction (source)
In one of the cells, type in =IMPORTHTML(“url-site“,“list”,<list_id>) where <list_id> is the list order in the url (either guess or iterate from 1 to XXX etc or use chrome developer tools to count the list num)
The above techniques can also apply to other websites that have list or table elements. For this project, one of the next step is to create flash cards video to help in the learning. With the table format in google sheets, it is easy to download the whole list or table as .CSV file and create in the form of flash cards. Check the link for the quick project.