In sentiment analysis or natural language processing, training sets are required to create the different classifiers in order to interpret phrases of words or assign appropriate sentiment features to particular phrases or texts . In general, the larger the training sets the higher the accuracy of the interpreted sentiment or results.
To produce a large training set, it is required to source manually large number of raw data and classifier them manually, which in turn, a tedious process. Google search results might be one alternative to collect the training sets which are already classified due to the defining boundaries set by the Google search keywords.
Hence, one of the way to create a large training set is to utilize the Google search module described in the previous post. We can input the description of the end target result (and hence, the classifier) and the google search will return the brief description. The brief description will usually contain snippets of news/event relate up to the events or end results. These provide the basis for the classifier.
An example of such use will be to classify stocks news into positive news (that make stocks prices rise) or negative news (that cause stock prices to fall). For positive stock outlook we can use the following keywords”Shares rise by xxx” or “Price jump”, the Google search results will return all the contents or news that have the keywords. This will eventually provide all the positive sentiment phrases or news that will predict whether prices increase or fall. The following diagram simplify the procedure.
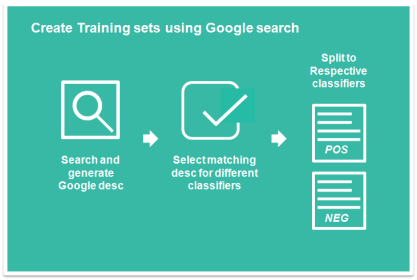
To make it easier for user to generate the classifier, a GUI function is created. Below GUI is generated using the wx,itempicker module. Users can input the google search texts (can have multiple entries separated by “;”) that will hint the classifiers and run the Google search and all the links results will be displayed on the left text box. The user can then proceed to select the items, After which all the items are selected, the user can proceed to save all the data in a file or copy to clipboard for further processing. While copying, it can append the classifier label to the sentences.
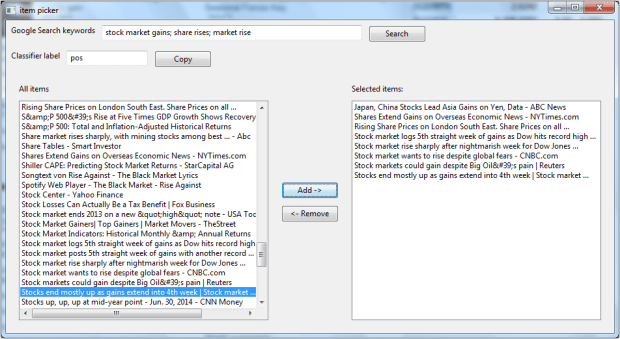
The final output are copied to clipboard. Below is the output. Note that commas except the classifier label parts are removed from the sentences.
Japan, China Stocks Lead Asia Gains on Yen Data – ABC News,pos
Shares Extend Gains on Overseas Economic News – NYTimes.com,pos
Rising Share Prices on London South East. Share Prices on all …,pos
Stock market logs 5th straight week of gains as Dow hits record high …,pos
Stock market rise sharply after nightmarish week for Dow Jones …,pos
Stock market wants to rise despite global fears – CNBC.com,pos
Stock markets could gain despite Big Oil’s pain | Reuters,pos
Stocks end mostly up as gains extend into 4th week | Stock market …,pos
Sample of the codes below. The code mainly used to define the various wx widgets. It requires the wx module and for the clipboard, it requires another script for the clipboard function. Alternatively, the copy function can be easily replaced by saving to target file or other storage.
import os, sys, time, datetime
## wx imports
import wx
from wx.lib.itemspicker import ItemsPicker,EVT_IP_SELECTION_CHANGED, IP_SORT_CHOICES
from wx.lib.itemspicker import IP_SORT_SELECTED,IP_REMOVE_FROM_CHOICES
## Google search module using python pattern
from Python_Google_Search_Retrieve import gsearch_url_form_class
## pyET_tools import, clipboard, for storing data to clipboard,
## can be substitued with alternative such as storing to file.
import pyET_tools.Clipboard_handler as Clip
class MyPanel(wx.Panel):
def __init__(self,parent):
wx.Panel.__init__(self,parent)
self.parent = parent
## list of parameters
self.google_results= []
self.add_classifier_str = 'pos' # add either classifer pos or neg to the str\
self.search_word_list = [] #
self.picked_item_list = []
## wx widgets
## Top panel display sizer for google search keywords input
## Hold the search Enter box and button to execute the search
## keywords are entered in single box but separate by ;
top_display_sizer = wx.BoxSizer(wx.HORIZONTAL)
search_label = wx.StaticText(self, -1, "Google Search keywords")
self.search_textbox = wx.TextCtrl(self, -1, size=(400, -1))
search_btn = wx.Button(self, -1, "Search")
search_btn.Bind(wx.EVT_BUTTON, self.OnSearch)
top_display_sizer.Add(search_label, 0, wx.ALL, 5)
top_display_sizer.Add(self.search_textbox, 0, wx.ALL, 5)
top_display_sizer.Add(search_btn, 0, wx.ALL, 5)
## Mid panel sizer
## Hold the classifier label Enter box and also the button for copy data to clipboard
## The button can be modified to save the picked items.
mid_display_sizer = wx.BoxSizer(wx.HORIZONTAL)
classifier_label = wx.StaticText(self, -1, "Classifier label")
copy_output_btn = wx.Button(self, -1, "Copy")
copy_output_btn.Bind(wx.EVT_BUTTON, self.CopyPickedItems)
self.classifier_textbox = wx.TextCtrl(self, -1, self.add_classifier_str, size=(125, -1))
mid_display_sizer.Add(classifier_label,0, wx.ALL, 5)
mid_display_sizer.Add(self.classifier_textbox, 0, wx.ALL, 5)
mid_display_sizer.Add(copy_output_btn, 0, wx.ALL, 5)
## Main sizer
## Item picker widgets.
main_sizer =wx.BoxSizer(wx.VERTICAL)
main_sizer.Add(top_display_sizer, 0, wx.TOP|wx.LEFT, 3)
main_sizer.Add(mid_display_sizer, 0, wx.TOP|wx.LEFT, 3)
self.ip = ItemsPicker(self,-1, [], 'All items', 'Selected items:',ipStyle = IP_SORT_CHOICES)
self.ip.Bind(EVT_IP_SELECTION_CHANGED, self.OnSelectionChange)
self.ip._source.SetMinSize((-1,150))
main_sizer.Add(self.ip, 1, wx.ALL|wx.EXPAND, 10)
self.SetSizer(main_sizer)
self.Fit()
def OnSearch(self,e):
""" Generate the list of google search results.
Set the items on the left textctrl box.
"""
gs_keywords_list = self.split_google_keywords()
self.OnGoogleRun(gs_keywords_list)
self.ip.SetItems(self.google_results)
def split_google_keywords(self):
""" Split the google keywords based on ";" for multiple keywords entry.
Returns:
(list): list of keywords to be used.
Remove any empty words accidentially bound by ;
"""
search_items = self.search_textbox.GetValue()
search_items_list = search_items.split(';')
return [n for n in search_items_list if n!='']
def append_classifier_to_text(self, selected_txt_list):
""" Add the classifier to the selected text.
Args:
selected_txt_list (list): list of str that contains the selected text.
Returns:
(list): list with classifer text added. eg. ",pos"
"""
return [n + ',' + self.add_classifier_str for n in selected_txt_list]
def get_classifier_txt(self):
""" Query and Set the classifier txt to self.add_classifier_str
Query from the self.classifier_textbox.
"""
self.add_classifier_str = self.classifier_textbox.GetValue()
def CopyPickedItems(self,e):
""" Copy the selected item to clipboard.
Get all the items on the selected list, append the pos str and save to clipboard
"""
## get classifier text
self.get_classifier_txt()
## get the picked items
selected_txt_list = self.picked_item_list
## append classifier text to picked items
selected_txt_list = self.append_classifier_to_text(selected_txt_list)
## copy the items to clipboard
Clip.copy_list_to_clipbrd(selected_txt_list)
def OnSelectionChange(self, e):
""" Trigger for the item picker when items are being selected or picked.
Set to self.picked_item_list.
"""
self.picked_item_list = e.GetItems()
def OnGoogleRun(self, search_words):
""" Run the google search results to get all the link
"""
## User options
NUM_SEARCH_RESULTS = 50 # number of search results returned
## Create the google search class
hh = gsearch_url_form_class(search_words)
hh.print_parse_results = 0
## Set the results
hh.set_num_of_search_results(NUM_SEARCH_RESULTS)
hh.enable_sort_date_descending()# enable sorting of date by descending. --> not enabled
## Generate the Url list based on the search item
url_list = hh.formed_search_url()
## Parse the google page based on the url
hh.parse_all_search_url()
hh.consolidated_results()
self.google_results = hh.merged_result_desc_list
print 'End Search'
class MyFrame(wx.Frame):
def __init__(self, parent, ID, title):
wx.Frame.__init__(self, parent, ID, title,pos=(50, 150), size=(950, 520))#size and position
self.top_panel = MyPanel(self)
class MyApp(wx.App):
def __init__(self):
wx.App.__init__(self,redirect =False)
self.frame= MyFrame(None,wx.ID_ANY, "item picker")
self.frame.Show()
def run():
try:
app = MyApp()
app.MainLoop()
except Exception,e:
print e
del app
if __name__== "__main__":
run()
(more…)