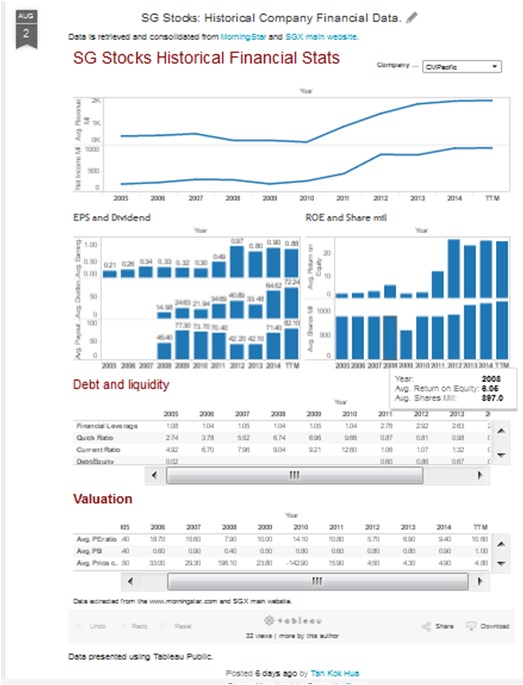
Getting price trends for stock analysis would require pulling of historical price data. Previous post has described various ways to pull the historical data from web. However, much time is wasted by scraping the data from web every time a trend is needed to be plotted or analyze. The more effective way is to store the data to a database (SQLite), update any new data to it and pull the respective data for analysis as needed.
Previous post have described the procedure for inputting the data to database. Here we integrate the various tools to create a database of historical prices and dividend payout. It utilizes the following to input the data to SQLite database:
- “Getting historical stock quotes and dividend Info using python” – this uses the Yahoo API to obtain historical prices which can be more than 10 years. It can also retrieve the dividend information which calculate the dividend payout timing and amount. This is being used to set up the database with the inital data. The data retrievial is relatively slow as it can only handle one stock at a time.
- “Get historical stock prices using Yahoo Query Language (YQL) and Python” – This is used for uploading recent data to the database given the advantage of pulling multiple stock data at single request using the YQL.
The above handles the downloading of the data to database. The transfer of downloaded data to sql database is easy with the help of pandas to_sql function again as described in the previous post. This allow easy handling of duplicated entries and addition of new data automatically.
Subsequently, to retrieve the data from database such as for “Basic Stock Technical Analysis with python“, we can make use of the SQLite command “Select * from histprice_table” to retrieve all the stock prices from the database. This is subsequently convert to Pandas Dataframe object to be used in cases where there is need for the historical data.
The following shows the sql database class. It has methods that can quickly build up database of historical price (see class method: setup_db_for_hist_prices_storage), update new data (see class method: scan_and_input_recent_prices) and retrieve the historical prices and dividend info from database (see class method: retrieve_hist_data_fr_db ). The number of data retrieved can be set using the date interval.
import re, sys, os, time, datetime, csv
import pandas
import sqlite3 as lite
from yahoo_finance_historical_data_extract import YFHistDataExtr
from Yahoo_finance_YQL_company_data import YComDataExtr #use for fast retrieval of data.
class FinanceDataStore(object):
""" For storing and retrieving stocks data from database.
"""
def __init__(self, db_full_path):
""" Set the link to the database that store the information.
Args:
db_full_path (str): full path of the database that store all the stocks information.
"""
self.con = lite.connect(db_full_path)
self.cur = self.con.cursor()
self.hist_data_tablename = 'histprice' #differnt table store in database
self.divdnt_data_tablename = 'dividend'
## set the date limit of extracting.(for hist price data only)
self.set_data_limit_datekey = '' #set the datekey so
## output data
self.hist_price_df = pandas.DataFrame()
self.hist_div_df = pandas.DataFrame()
def close_db(self):
""" For closing the database. Apply to self.con
"""
self.con.close()
def break_list_to_sub_list(self,full_list, chunk_size = 45):
""" Break list into smaller equal chunks specified by chunk_size.
Args:
full_list (list): full list of items.
Kwargs:
chunk_size (int): length of each chunk.
Return
(list): list of list.
"""
if chunk_size < 1:
chunk_size = 1
return [full_list[i:i + chunk_size] for i in range(0, len(full_list), chunk_size)]
def setup_db_for_hist_prices_storage(self, stock_sym_list):
""" Get the price and dividend history and store them to the database for the specified stock sym list.
The length of time depends on the date_interval specified.
Connection to database is assuemd to be set.
For one time large dataset (where the hist data is very large)
Args:
stock_sym_list (list): list of stock symbol.
"""
## set the class for extraction
histdata_extr = YFHistDataExtr()
histdata_extr.set_interval_to_retrieve(360*5)# assume for 5 years information
histdata_extr.enable_save_raw_file = 0
for sub_list in self.break_list_to_sub_list(stock_sym_list):
print 'processing sub list', sub_list
histdata_extr.set_multiple_stock_list(sub_list)
histdata_extr.get_hist_data_of_all_target_stocks()
histdata_extr.removed_zero_vol_fr_dataset()
## save to one particular funciton
#save to sql -- hist table
histdata_extr.processed_data_df.to_sql(self.hist_data_tablename, self.con, flavor='sqlite',
schema=None, if_exists='append', index=True,
index_label=None, chunksize=None, dtype=None)
#save to sql -- div table
histdata_extr.all_stock_div_hist_df.to_sql(self.divdnt_data_tablename, self.con, flavor='sqlite',
schema=None, if_exists='append', index=True,
index_label=None, chunksize=None, dtype=None)
self.close_db()
def scan_and_input_recent_prices(self, stock_sym_list, num_days_for_updates = 10 ):
""" Another method to input the data to database. For shorter duration of the dates.
Function for storing the recent prices and set it to the databse.
Use with the YQL modules.
Args:
stock_sym_list (list): stock symbol list.
Kwargs:
num_days_for_updates: number of days to update. Cannot be set too large a date.
Default 10 days.
"""
w = YComDataExtr()
w.set_full_stocklist_to_retrieve(stock_sym_list)
w.set_hist_data_num_day_fr_current(num_days_for_updates)
w.get_all_hist_data()
## save to one particular funciton
#save to sql -- hist table
w.datatype_com_data_allstock_df.to_sql(self.hist_data_tablename, self.con, flavor='sqlite',
schema=None, if_exists='append', index=True,
index_label=None, chunksize=None, dtype=None)
def retrieve_stocklist_fr_db(self):
""" Retrieve the stocklist from db
Returns:
(list): list of stock symbols.
"""
command_str = "SELECT DISTINCT SYMBOL FROM %s "% self.hist_data_tablename
self.cur.execute(command_str)
rows = self.cur.fetchall()
self.close_db()
return [n[0].encode() for n in rows]
def retrieve_hist_data_fr_db(self, stock_list=[], select_all =1):
""" Retrieved a list of stocks covering the target date range for the hist data compute.
Need convert the list to list of str
Will cover both dividend and hist stock price
Kwargs:
stock_list (list): list of stock symbol (with .SI for singapore stocks) to be inputted.
Will not be used if select_all is true.
select_all (bool): Default to turn on. Will pull all the stock symbol
"""
stock_sym_str = ''.join(['"' + n +'",' for n in stock_list])
stock_sym_str = stock_sym_str[:-1]
#need to get the header
command_str = "SELECT * FROM %s where symbol in (%s)"%(self.hist_data_tablename,stock_sym_str)
if select_all: command_str = "SELECT * FROM %s "%self.hist_data_tablename
self.cur.execute(command_str)
headers = [n[0] for n in self.cur.description]
rows = self.cur.fetchall() # return list of tuples
self.hist_price_df = pandas.DataFrame(rows, columns = headers) #need to get the header?? how to get full data from SQL
## dividend data extract
command_str = "SELECT * FROM %s where symbol in (%s)"%(self.divdnt_data_tablename,stock_sym_str)
if select_all: command_str = "SELECT * FROM %s "%self.divdnt_data_tablename
self.cur.execute(command_str)
headers = [n[0] for n in self.cur.description]
rows = self.cur.fetchall() # return list of tuples
self.hist_div_df = pandas.DataFrame(rows, columns = headers) #need to get the header?? how to get full data from SQL
self.close_db()
def add_datekey_to_hist_price_df(self):
""" Add datekey in the form of yyyymmdd for easy comparison.
"""
self.hist_price_df['Datekey'] = self.hist_price_df['Date'].map(lambda x: int(x.replace('-','') ))
def extr_hist_price_by_date(self, date_interval):
""" Limit the hist_price_df by the date interval.
Use the datekey as comparison.
Set to the self.hist_price_df
"""
self.add_datekey_to_hist_price_df()
target_datekey = self.convert_date_to_datekey(date_interval)
self.hist_price_df = self.hist_price_df[self.hist_price_df['Datekey']>=target_datekey]
def convert_date_to_datekey(self, offset_to_current = 0):
""" Function mainly for the hist data where it is required to specify a date range.
Default return current date. (offset_to_current = 0)
Kwargs:
offset_to_current (int): in num of days. default to zero which mean get currnet date
Returns:
(int): yyymmdd format
"""
last_eff_date_list = list((datetime.date.today() - datetime.timedelta(offset_to_current)).timetuple()[0:3])
if len(str(last_eff_date_list[1])) == 1:
last_eff_date_list[1] = '0' + str(last_eff_date_list[1])
if len(str(last_eff_date_list[2])) == 1:
last_eff_date_list[2] = '0' + str(last_eff_date_list[2])
return int(str(last_eff_date_list[0]) + last_eff_date_list[1] + str(last_eff_date_list[2]))