For those who looking for Git Hub projects to contribute to:
Author: Kok Hua
Python pattern for natural language processing
Python pattern is a good alternative to NLTK with its lightweight and extensive features in natural language processing. In addition, it also have the capability to act as a web crawler and able to retrieve information from twitter, facebook etc. The full functionality can be summarized as stated from their website:
“Pattern is a web mining module for the Python programming language.
It has tools for data mining (Google, Twitter and Wikipedia API, a web crawler, a HTML DOM parser), natural language processing (part-of-speech taggers, n-gram search, sentiment analysis, WordNet), machine learning (vector space model, clustering, SVM), network analysis and <canvas> visualization.”
Below python script illustrate some of the functionality of Python Pattern. I intend to use some of the functions for the google search module developed previously.
The script crawl a particular website, get the plain text of the web page and processed it to remove short sentences (eg links) . After which it will get the top x number of high frequency words found in the web page. After which it will search for all the phrases in the text that contain the high frequency words.
The script still require a number of improvement. For example, keyword ‘turbine’ and ‘turbines’ should be same word and need to classify as one word.
import sys, os, time
from pattern.en import parse, Sentence, parsetree, tokenize
from pattern.search import search
from pattern.vector import count, words, PORTER, LEMMA, Document
from pattern.web import URL, plaintext
def get_plain_text_fr_website(web_address):
""" Scrape plain text from a web site.
Args:
web_address (str): web http address.
Returns:
(str): plain text in str.
"""
s = URL(web_address).download()
## s is html format.
return convert_html_to_plaintext(s)
def convert_html_to_plaintext(html):
""" Take in html and output as text.
Args:
html (str): str in html format.
Returns:
(str): plain text in str.
TODO: include more parameters.
"""
return plaintext(html)
def retain_text_with_min_sentences_len(raw_text,len_limit =6 ):
""" Return paragraph with sentences having certain number of length limit.
Args:
raw_text (str): text input in paragraphs.
len_limit (int): min word limit.
Returns:
(str): modified text with min words in sentence
"""
sentence_list = get_sentences_with_min_words(split_text_to_list_of_sentences(raw_text), len_limit)
return ''.join(sentence_list)
def split_text_to_list_of_sentences(raw_text):
""" Split the raw text into list of sentences.
Args:
raw_text (str): text input in paragraphs.
Returns:
(list): list of str of sentences.
"""
return tokenize(raw_text)
def get_sentences_with_min_words(sentences_list, len_limit):
""" Return list of sentences with number of words greater than specified len_limit.
Args:
sentences_list (list): sentences break into list.
len_limit (int): min word limit.
Returns:
(list): list of sentences with min num of words.
"""
return [n for n in sentences_list if word_cnt_in_sent(n) >= len_limit]
def word_cnt_in_sent(sentence):
""" Return number of words in a sentence. Use spacing as relative word count.
Count number of alphanum words after splitting the space.
Args:
sentence (str): Proper sentence. Can be split from the tokenize function.
Returns:
(int): number of words in sentence.
"""
return len([ n for n in sentence.split(' ') if n.isalnum()]) + 1
def retrieve_string(match_grp):
""" Function to retrieve the string from the pattern.search.Match class
Args:
match_grp (pattern.search.Match): match group
Returns:
(str): str containing the words that match
Note:
Does not have the grouping selector
"""
return match_grp.group(0).string
def get_top_freq_words_in_text(txt_string, top_count, filter_method = lambda w: w.lstrip("\'").isalnum(),exclude_len = 0):
""" Method to get the top frequency of words in text.
Args:
txt_string (str): Input string.
top_count (int): number of top words to be returned.
Kwargs:
filter_method (method): special character to ignore, in some cases numbers may also need to ignore.
pass in lambda function.
Default accept method that include only alphanumeric
exclude_len (int): exclude keyword if len less than certain len.
default 0, which will not take effect.
Returns:
(list): list of top words """
docu = Document(txt_string, threshold=1, filter = filter_method)
## Provide extra buffer if there is word exclusion
freq_keyword_tuples = docu.keywords(top=top_count )
## encode for unicode handliing
if exclude_len == 0:
return [n[1].encode() for n in freq_keyword_tuples]
else:
return [n[1].encode() for n in freq_keyword_tuples if not len(n[1])<=exclude_len]
def get_phrases_contain_keyword(text_parsetree, keyword, print_output = 0, phrases_num_limit =5):
""" Method to return phrases in target text containing the keyword. The keyword is taken as an Noun or NN|NP|NNS.
The phrases will be a noun phrases ie NP chunks.
Args:
text_parsetree (pattern.text.tree.Text): parsed tree of orginal text
keyword (str): can be a series of words separated by | eg "cat|dog"
Kwargs:
print_output (bool): 1 - print the results else do not print.
phrases_num_limit (int): return the max number of phrases. if 0, return all.
Returns:
(list): list of the found phrases. (remove duplication )
TODO:
provide limit to each keyword.
"""
## Regular expression matching.
## interested in phrases containing the traget word, assume target noun is either adj or noun
target_search_str = 'JJ|NN|NNP|NNS?+ ' + keyword + ' NN|NNP|NNS?+'
target_search = search(target_search_str, text_parsetree)# only apply if the keyword is top freq:'JJ?+ NN NN|NNP|NNS+'
target_word_list = []
for n in target_search:
if print_output: print retrieve_string(n)
target_word_list.append(retrieve_string(n))
target_word_list_rm_duplicates = rm_duplicate_keywords(target_word_list)
if (len(target_word_list_rm_duplicates)>= phrases_num_limit and phrases_num_limit>0):
return target_word_list_rm_duplicates[:phrases_num_limit]
else:
return target_word_list_rm_duplicates
def rm_duplicate_keywords(target_wordlist):
""" Method to remove duplication in the key word.
Args:
target_wordlist (list): list of keyword str.
Returns:
(list): list of keywords with duplicaton removed.
"""
return list(set(target_wordlist))
if __name__ == '__main__':
## random web site for extraction.
web_address = 'http://en.wikipedia.org/wiki/Turbine'
## extract the plain text.
webtext = get_plain_text_fr_website(web_address)
## modified plain text so that it can remove those very short sentences (such as side bar menu).
modifed_text = retain_text_with_min_sentences_len(webtext)
## Begin summarizing the important pt of the website.
## first step to get the top freq words, here stated 10.
## Exclude len will remove any length less than specified, here stated 2.
list_of_top_freq_words = get_top_freq_words_in_text(modifed_text, 4, lambda w: w.lstrip("'").isalpha(),exclude_len = 2)
print list_of_top_freq_words
## >> ['turbine', 'turbines', 'fluid', 'impulse']
## Parse the whole document for analyzing
## The pattern.en parser groups words that belong together into chunks.
##For example, the black cat is one chunk, tagged NP (i.e., a noun phrase)
t = parsetree(modifed_text, lemmata=True)
## get target search phrases based on the top freq words.
for n in list_of_top_freq_words:
print 'keywords: ', n
print get_phrases_contain_keyword(t, n)
print '*'*8
##>> keywords: turbine
##>> [u'the Francis Turbine', u'the marine turbine', u'most turbines', u'impulse turbines .Reaction turbines', u'turbine']
##>> ********
##>> keywords: turbines
##>> [u'de Laval turbines', u'possible .Wind turbines', u'type .Very high efficiency steam turbines', u'conventional steam turbines', u'draft tube .Francis turbines']
##>> ********
##>> keywords: fluid
##>> [u'a fluid', u'working fluid', u'a high velocity fluid', u'fluid', u'calculations further .Computational fluid']
##>> ********
##>> keywords: impulse
##>> [u'equivalent impulse', u'impulse', u'Pressure compound multistage impulse', u'de Laval type impulse', u'traditionally more impulse']
##>> ********
</pre>
<pre>
Scaping google results using python (Updates)
I modified the Google search module described in previous post. The previous limitation of the module to search for more than 100 results is removed.It can now search and process any number of search results defined by the users (also subjected to the number of results returned by Google.)
The second feature include passing the keywords as a list so that it can search more than one search key at a time.
As mentioned in the previous post, I have added a GUI version using wxpython to the script. I will modify the GUI script to take in multiple keywords.
Parsing Dict object from text file (More…)
I have modified the DictParser ,mentioned in previous blog, to handle object parsing. Previous version of DictParser can only handle basic data type, whereas in this version, user can pass a dict of objects for the DictParser to identify and it will replace those variables marked with ‘@’, treating them as objects.
An illustration is as below. Note the “second” key has an object @a included in the value list. This will be subsequently substitute by [1,3,4] after parsing.
## Text file
$first
aa:bbb,cccc,1,2,3
1:1,bbb,cccc,1,2,3
$second
ee:bbb,cccc,1,2,3
2:1,bbb,@a,1,2,3
## end of file
The output from DictParser are as followed:
p = DictParser(temp_working_file, {'a':[1,3,4]}) #pass in a dict with obj def
p.parse_the_full_dict()
print p.dict_of_dict_obj
>>> {'second': {'ee': ['bbb', 'cccc', 1, 2, 3], 2: [1, 'bbb', [1, 3, 4], 1, 2, 3]},
'first': {'aa': ['bbb', 'cccc', 1, 2, 3], 1: [1, 'bbb', 'cccc', 1, 2, 3]}}
If the object is not available or not pass to DictParser, it will be treated as string.
Using the ‘@’ to denote the object is inspired by the Julia programming language where $xxx is used to substitute objects during printing.
Scaping google results using python (GUI version)
I add a GUI version using wxpython to the script as described in previous post.
The GUI version enable display of individual search results in a GUI format. Each search results can be customized to have the title, link, meta body description, paragraphs on the main page. That is all that is displayed in the current script, I will add in the summarized text in future.
There is also a separate textctrl box for entering any notes based on the results so that user can copy any information to the textctrl box and save it as separate files. The GUI is shown in the picture below.
The GUI script is found in the same Github repository as the google search module. It required one more module which parse the combined results file into separate entity based on the search result number. The module is described in the previous post.
The parsing of the combined results file is very simple by detecting the “###” characters that separate each results and store them individually into a dict. The basic code is as followed.
key_symbol = '###' combined_result_list,self.page_scroller_result = Extract_specified_txt_fr_files.para_extract(r'c:\data\temp\htmlread_1.txt',key_symbol, overlapping = 0 )

Rapid generation of powerpoint report with template scanning
In my work, I need to create PowerPoint (ppt) report of similar template. For the report, I need to create various plots in Excel or JMP, save it to folders and finally paste them to ppt. It be great if it is possible to generate ppt report rapidly by using automation. I have created a python interface to powerpoint using com commands hoping it will help to generate the report automatically.
The initial idea is to add command to paste the plots at specific slides and specific positions. The problem with this is that I have to set the position values and picture sizes for each graph in the python script. This become tedious and have to set independently for each report type.
The new idea will be to give the script a scanned template and the script will do the following commands:
- Create a template ppt with the graphs at particular slide, position and size set.
- Rename each object that you need to copy with the keywords such as ‘xyplot_Qty_year’ which after parsing will require a xyplot with qty as y axis and year as x axis. This will then get the corresponding graph with the same type and qty path and link them together.
- See the link on how to rename objects.
- The script will scan through all the slide, getting all info of picture that need to be pasted by having the keyword. It will note the x and y positon and the size.
- The script will then search the required folder for the saved pic file of the same type and will paste them to a new ppt.
The advantage of this approach is that multiple scanned template can be created. The picture position can be adjusted easily as well.
Sample of the script is as below. It is not a fully executable script.
import os
import re
import sys
import pyPPT
class ppt_scanner(object):
def __init__(self):
# ppt setting
self.ppt_scanned_filename = r'\\SGP-L071166D033\Chengai main folder\Chengai setup files\scanned_template.ppt'
# scanned plot results
self.full_scanned_info = dict()
self.scanned_y_list = list()
# plots file save location where keyword is the param scanned
self.bivar_plots_dict = dict()# to be filled in
#ppt plot results
##store the slide no and the corresponding list of pic
self.ppt_slide_bivar_pic_name_dict = dict()
def initialize_ppt(self):
'''
Initialize the ppt object.
Open the template ppt and save it to target filename as ppt and work it from there
None --> None (create the ppt obj)
'''
self.pptobj = UsePPT() # New ppt for pasting the results.
self.pptobj.show()
self.pptobj.save(self.ppt_save_filename)
self.scanned_template_ppt = UsePPT(self.ppt_scanned_filename) # Template for new ppt to follow
self.scanned_template_ppt.show()
def close_all_ppt(self):
""" Close all existing ppt.
"""
self.pptobj.close()
self.scanned_template_ppt.close()
## Scanned ppt obj function
def get_plot_info_fr_scan_ppt_slide(self, slide_no):
""" Method (pptobj) to get info from template scanned ppt.priorty to get the x, y coordinates of pasting.
Only get the Object name starting with plot.
Straight away stored info in various plot classification
Args:
Slide_no (int): ppt slide num
Returns:
(list): properties of all objects in slide no
"""
all_obj_list = self.scanned_template_ppt.get_all_shapes_properties(slide_no)
self.classify_info_to_related_group(slide_no, [n for n in all_obj_list if n[0].startswith("plot_")] )
return [n for n in all_obj_list if n[0].startswith("plot_")]
def get_plot_info_fr_all_scan_ppt_slide(self):
""" Get all info from all slides. Store info to self.full_scanned_info.
"""
for slide_no in range(1,self.scanned_template_ppt.count_slide()+1,1):
self.get_plot_info_fr_scan_ppt_slide(slide_no)
def classify_info_to_related_group(self, slide_no, info_list_fr_one_slide):
"""Group to one consolidated group: main dict is slide num with list of name, pos as key.
Append to the various plot groups. Get the keyword name and the x,y pos.
Will also store the columns for the y-axis (self.scanned_y_list).
Args:
slide_no (int): slide num to place in ppt.
info_list_fr_one_slide (list):
"""
temp_plot_biv_info, temp_plot_tab_info, temp_plot_legend_info = [[],[],[]]
for n in info_list_fr_one_slide:
if n[0].startswith('plot_biv_'):
temp_plot_biv_info.append([n[0].encode().replace('plot_biv_',''),n[1],n[2], n[3], n[4]])
self.scanned_y_list.append(n[0].encode().replace('plot_biv_',''))
self.ppt_slide_bivar_pic_name_dict[slide_no] = temp_plot_biv_info
## pptObj -- handling the pasting
def paste_all_plots_to_all_ppt_slide(self):
""" Paste the respective plots to ppt.
"""
## use the number of page as scanned template
for slide_no in range(1,self.pptobj.count_slide()+1,1):
self.paste_plots_to_slide(slide_no)
def paste_plots_to_slide(self, slide_no):
""" Paste all required plots to particular slide
Args:
slide_no (int): slide num to place in ppt.
"""
## for all biv plots
for n in self.ppt_slide_bivar_pic_name_dict[slide_no]:
if self.bivar_plots_dict.has_key(n[0]):
filename = self.bivar_plots_dict[n[0]]
pic_obj = self.pptobj.insert_pic_fr_file_to_slide(slide_no, filename, n[1], n[2], (n[4],n[3]))
if (__name__ == "__main__"):
prep = ppt_scanner()
prep.initialize_ppt()
## scanned all info -- scanned template function
prep.get_plot_info_fr_all_scan_ppt_slide()
prep.scanned_template_ppt.close()
## paste plots
prep.paste_all_plots_to_all_ppt_slide()
prep.pptobj.save()
print 'Completed'
Parsing Dict object from text file (Updates)
I have been using the DictParser created as mentioned in previous blog in a recent project to create a setting file for various users. In the project, different users need to have different settings such as parameter filepath.
The setting file created will use the computer name to segregate the different users. By creating a text file (with Dict Parser) based on the different computer names, it is easy to get separate setting parameters for different users. Sample of the setting file are as below.
## Text file $USER1_COM_NAME #setting_comment_out:r'c:\data\temp\bbb.txt' setting2:r'c:\data\temp\ccc.txt' $USER2_COM_NAME setting:r'c:\data\temp\eee.txt' 2:1,bbb,cccc,1,2,3 ## end of file
The output from DictParser are as followed:
## python output as one dict containing two dicts with different user'USER1_COM_NAME' and 'USER2_COM_NAME'
>> {'USER1_COM_NAME': {'setting2': ['c:\\data\\temp\\ccc.txt']}, 'USER2_COM_NAME': {2: [1, 'bbb', 'cccc', 1, 2, 3], 'setting': ['c:\\data\\temp\\eee.txt']}}
User can use the command “os.environ[‘ComputerName’]” to get the corresponding setting filepath.
I realized that the output format is somewhat similar to json format. This parser is more restrictive in uses hence has some advantage over json in less punctuations (‘{‘, ‘\’) etc and able to comment out certain lines.
Parsing dict object from text file
Sometimes we need to store the different settings in a text file. Getting the different configurations will be easier if each particular setting group is a dict with the different key value pairs. The dict objects can be passed to other functions or modules with ease.
I created the following script that is able to parse the strings from a text file as separate dict obj with base type. This allows user to create the dict object easily in a text file. As for now, the values the dict can take basic type such as int, float and string.
Creating the text file format is simple. Starting a dict on a new line with $ <dict name> followed by the key value pairs in each subsequent line. The format for the pair is <key>:<value1,value2…>
Example of a file format used is as below:
## Text file $first aa:bbb,cccc,1,2,3 1:1,bbb,cccc,1,2,3 $second ee:bbb,cccc,1,2,3 2:1,bbb,cccc,1,2,3 ## end of file
## python output as one dict containing two dicts with name 'first' and 'second'
>> {'first': {'aa':['bbb','cccc',1,2,3],1:[1,'bbb','cccc',1,2,3]},
'second': {'ee':['bbb','cccc',1,2,3],2:[1,'bbb','cccc',1,2,3]}}
The script is relatively simple, making use of the literal_eval method in ast module to convert the string to various base type. It does not have the danger of eval() method. Below is the code for the method for string conversion.
def convert_str_to_correct_type(self, target_str):
""" Method to convert the str repr to the correct type
Idea from http://stackoverflow.com/questions/2859674/converting-python-list-of-strings-to-their-type
Args:
target_str (str): str repr of the type
Returns:
(str/float/int) : return the correct representation of the type
"""
try:
return ast.literal_eval(target_str)
except ValueError:
## not converting as it is string
pass
return target_str
The rest of script is the reading of the different line and parsing it with correct info. The method can be summarized as below method call.
def parse_the_full_dict(self):
"""Method to parse the full file of dict
Once detect dict name open the all the key value pairs
"""
self.read_all_data_fr_file()
self.dict_of_dict_obj = {}
## start parsing each line
## intialise temp_dict obj
start_dict_name = ''
for line in self.filedata:
if self.is_line_dict_name(line):
start_dict_name = self.parse_dict_name(line)
## intialize the object
self.dict_of_dict_obj[start_dict_name] = dict()
elif self.is_line_key(line):
temp_key, temp_value = self.parse_key(line)
self.dict_of_dict_obj[start_dict_name][temp_key] = temp_value
The next more complicated case is to handle list of list and also user objects. I do not have any ideas on how to do it yet….
Good introduction to unittest and mock
Good introduction to unittest and mock
Good presentation on introduction to testing by Ned Batchelder (PyCon US 2014). Simple and easy way to start testing your python modules.
Extracting portions of text from text file
I was trying to read the full book of abstracts from a conference earlier and finding it tedious to copy portions of desired paragraphs for my summary report to be fed into my simple auto-summarized module.
I came up with the following script that allows users to put a specific symbol such as “@” at the start and end of the paragraph to mark those paragraphs or sentences to be extracted. More than one portion can be selected and they can be returned as a list for further processing. For my case, each of the paragraph outputted will be auto summarized.
The following diagram illustrated the two different kinds of extraction.
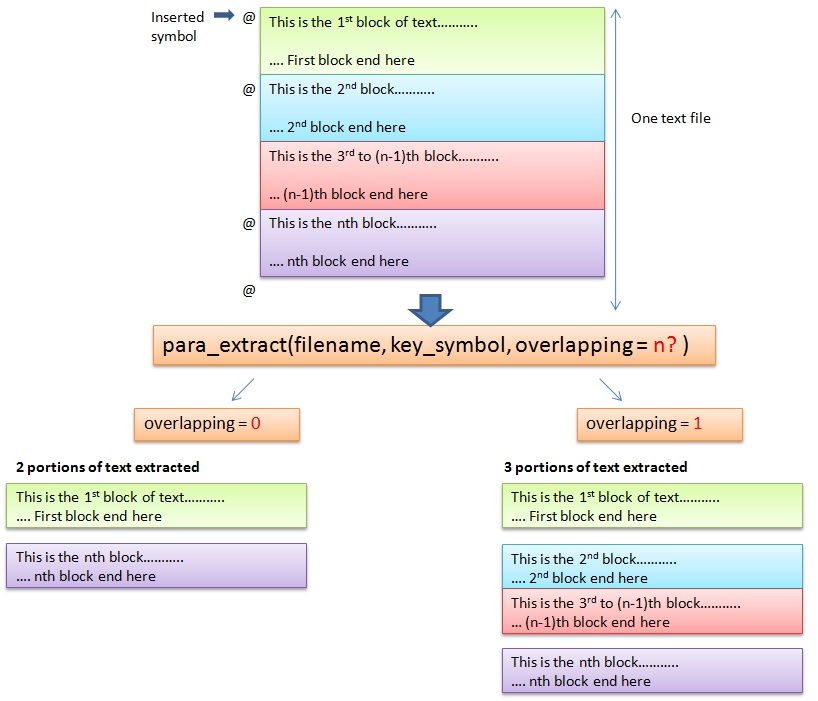
The script scans all the lines of the text file, looking for the key_symbol (“@” in this case) and marks the index of the selected lines. The present method only use string “startwith” function. It can be expanded to be using regular expression.
Depending on the mode (overlapping or non-overlapping), it will calculate the portion of the text to be selected and output as a list which can be use for further processing.
Script can be found here.
